Quando eu estava na faculdade, lembro que tive a honra de aprender algo que passa despercebido por muitos desenvolvedores. Meu professor de algoritmos, que também foi meu coordenador, ensinou nossa turma sobre a conceituação das variáveis em relação aos seus respectivos tamanhos (bits) – o uso adequado de cada uma delas para cada caso concreto, pois isso é uma das poucas coisas que garante o mínimo de processamento ao escrever códigos.
Na minha cabeça imaginativa na época, eu ficava pensando no código-fonte dos firmwares dos routers sendo executado pela CPU dos próprios, especialmente nesses produtos plug-and-play, onde o escopo do produto é ter um custo baixo para o consumidor, porque a CPU, por regra, tem capacidade limitada (custo barato). Imaginava alguém desenvolvendo um código cujo objetivo é evitar o overhead (esgotamento de recursos da CPU) no router, porque imagine só uma CPU sendo chamada o tempo inteiro para percorrer uma tabela de roteamento a cada pacote de dados que passa para saber para qual interface redirecionar? Hahahahaha, enfim, aí entra a memória cache e blah blah blah…
Indo direto ao ponto: com base nesse cenário de considerar o mínimo possível de processamento (recursos de CPU) que o código demandará, é que vai definir se uma determinada aplicação possui desempenho ou não. Essa é uma das características de Qualidade de um Produto de software para o cliente, sem contar também que essa otimização atrai benefícios evitando substituições de ativos em caso de servidores on-premises e, no caso de aplicações sendo executadas em Cloud, pior ainda, porque os custos aumentam conforme se usam mais recursos.
Geralmente, o mercado das empresas de tecnologia desenvolve aplicações que retornam os dados processados por meio de linguagens de backend como Java, C#, PHP, Python, Node, entre outras. Enfim, por meio de alguma biblioteca para o tipo de SGBD é que essas aplicações interagem com a base de dados, independente da arquitetura adotada na aplicação, seja monolítica, de microserviços, etc. Porém, para fins de Desempenho (experiência do usuário), é preferível respeitar um processo padrão muito conhecido na área de Data Science, chamado ETL – Extract, Transform, Load, como ilustra a figura abaixo:
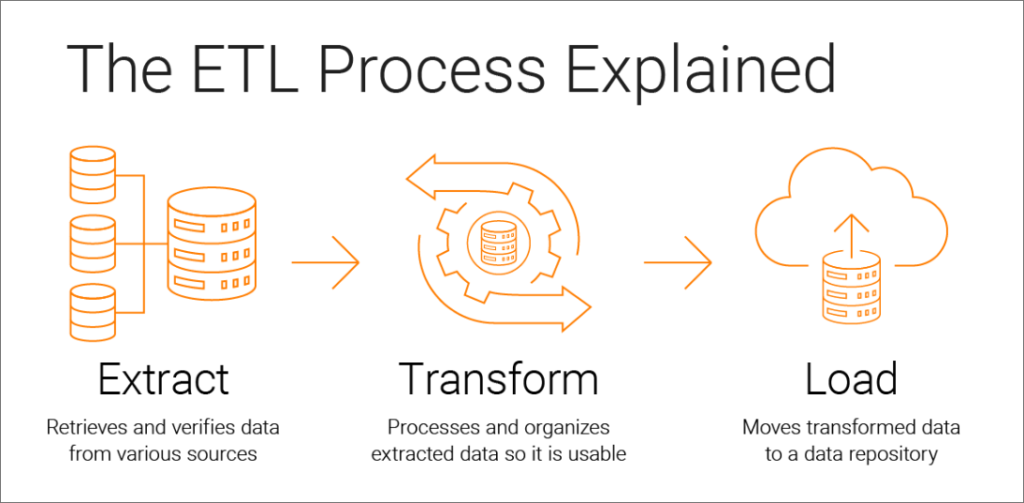
Geralmente, as linguagens de programação supracitadas são usadas na etapa do T-Transform, onde não é recomendado criar ciclos de processamento para evitar uso demasiado de CPU nos servidores. Essa etapa é mais usada para Validações e Tratamento de Erros, mas o que puder ser feito para processar do lado E-Extract (linguagem SQL) é melhor para fins de desempenho. Enfim, o L-Load é onde os dados processados serão apresentados ao Front-End, seja em um dashboard, tabela, etc.
Enfim, o produto é para o cliente! Colocar-se no lugar do cliente ao desenvolver/manter uma aplicação é essencial para a construção e manutenção de bons produtos.

Desenvolvedor full-stack, formado em Ciência da Computação e Redes de Computadores, com certificações internacionais da AWS e IBM. Atuou em projetos de inovação tecnológica no governo de Portugal. Atualmente, trabalha com processamento de dados IoT na telemetria de grandes frotas de veículos em todo o continente europeu, visando otimizar processos, reduzir custos e minimizar impactos ambientais.